تعریف
در یادگیری تقویتی (reinforcement learning) اتحاد زیر به وسیله تابع Q زیر بهینه میشود.
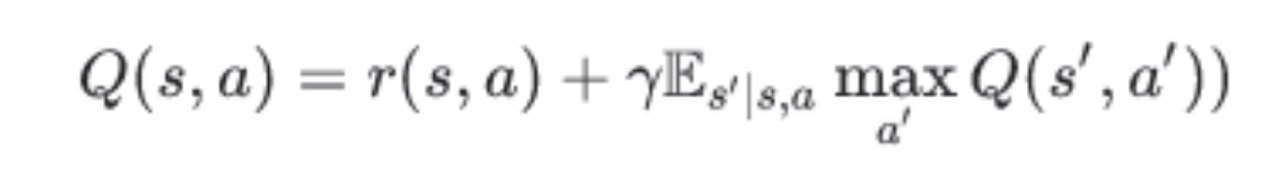
یادگیری تقویتی با اعمال این اتحاد به یادگیری Q با قاعده بهروزرسانی زیر منجر میشود:
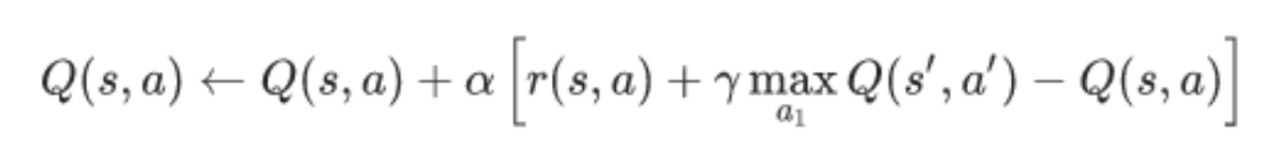
معادله بلمن علاوه بر یادگیری تقویتی کاربردهایی در برنامهنویسی پویا نیز دارد.
اطلاعات بیشتر: معادله بلمن در ویکیپدیا
آخرین ویرایش:
۲۳ شهریور ۱۳۹۹

